Shorthands
Posts in this series:
Abba
2014-03-19
My first major project at Hacker School is called Abba, the Abbreviation Engine. In order to understand why Abba exists I need to backtrack a little.
The New Abbreviations
Since around 2006 I have written in an alphabetic shorthand that I call (when I have to write about it in places like this) the New Abbreviations. When asked for a snappy one-line I say it’s basically a ‘human-readable non-lossy compression algorithm for text’. It’s also of the same general family as the abbreviationes of the Middle Ages. It looks like this:

Very simply, the New Abbreviations (and alphabetic shorthands in general) are a matter of matching some simple lettern patterns and replacing them with different symbols.
I’ve written this way for a while. It’s a long-standing project of mine of which I’m rather fond. And on the face of it, this should be very simple to digitize.
There are just a couple factors which make it non-trivial to implement as a simple set of find-and-replace rules:
Positioning rules. This shorthand was designed with English text in mind, and so there are certain assumptions about character placement built in. For instance: one very common word that’s abbreviated in this shorthand is the word “we”, which comes out as w̃. That’s pretty readable, especially when you combine it with its fellows, m̃ for “me” and ũ for “us”. But it wouldn’t be as useful to read and write if you simply replaced the sequence “we” every time those two letters came together, leaving sw̃ll and sw̃ep and others. So you replace “we” the word only when it stands alone. And similarly, you replace the prefix “con” and the suffix “ion”. So you need to translate human understandings of morphology, to an extent, into abbreviation rules.
Non-Unicode glyphs. Above we saw that “we” gets abbreviated as w̃, which is all well and good because we can type out w̃ with relatively little difficulty. But shorthands are not typed, they’re written; and thus they’ll tend to contain symbols that you can’t necessarily represent in computer text—and certainly not with perfect semantic fidelity. In my shorthand, for instance, “er”, when found in the middle of a word, is rendered with a little curlicue above the x-height, as seen in the wikipedia entry for Scribal Abbrevations under “forms”. There’s no unicode character for that that I’ve been able to find. So you can’t simply replace several letters with one letter—sometimes what you’re inserting won’t be a letter at all.
Implementation
It was with these technical hurdles in mind that I decided to come up with a Python application that could do the work of my shorthand system.
Of course, it would hardly be worth my while to write a program that only spoke the New Abbreviations. It only made sense to write a more generic shorthand engine, which could understand the NA as a ruleset, as well as any other hypothetical alphabetical shorthand that somebody else might like to come up with.
In any case, the first thing I knew was that you couldn’t just stick funny unicode letters into a given text and call it a day. If you could I never would have written a program in the first place; I would have just assembled a huge unwieldy collection of unicode symbols and sufficed myself with a lot of copy and pasting.
Instead, I figured: since strings and lists (of characters) are so closely related in Python, why not replace the sequences of characters you want to replace with abbreviation objects, that can report on their own realization? That way you don’t have to be confined to the Unicode character set when defining your abbreviations.
For the first day I continued in this vein, and actually came up with a working prototype. Unfortunately the code was turning out nearly unmaintainable. There was too much strain and accounting for the fact that when dealing with a heterogenous list you never knew what type of thing the next element in your list would be. So every list operation ended up having to wrap itself in checks for element types. And the regexes that determine string replacement don’t make any sense when applied to non-text objects.
The Dark Heart of Abba
The breakthrough came with the idea to use Unicode private use characters to stand in for abbreviations in a string. A brief primer:
Unicode Private Use Areas
Unicode, you may or may not know, is a text encoding standard for representing a much wider range of characters than just the Latin alphabet encoded in ASCII. The general aim of this sort of thing is to provide a standard encoding for any letter or character in any language in the world. It’s organized by blocks of codepoints, where each codepoint is the hexadecimal number assoociated with the encoded character. The Unicode character ‘a’, for instance, has the hex codepoint 0x061, which is 97 in decimal. The Gurmukhi letter ‘ਉ’ has the hex codepoint 0xa09, which is 2569. It’s the 2569th character in the Unicode character set.
The 57344th character in the Unicode charset, at codepoint 0xE000, doesn’t have a character associated with it. That its whole function, actually—to not have a letter associated with it. It’s a Unicode codepoint that acts like a character and can live in a string with other characters but it has no standardized content associated with it. The whole block of which it is the first character is the Private Use Area.
Using Private Use Characters as Abbreviations
So, if we use the Private Use Area of the Basic Multilingual Plane of the Unicode standard, we have 6400 codepoints that we can insert into our text with the near-certainty that they won’t already be there. And then we can treat our list of chars like a real grown-up string.
def __init__(self, config):
self.abb_sequences = []
self.lookup_table = {}
# begin creating unicode characters at the beginning
# of the private use space
self.pool = iter(range(57344,63743))
rep_search = re.compile("_rep$")
# Read through the config file, pulling out abbreviation schemae
for section in config.sections():
has_a_rep = False
# Pull a control character from the pool
codepoint = chr(next(self.pool))
# Analyze the regnet markup and move it into the abbreviation dict
self.add_to_sequences(section, regnet.Regnet(config[section]['pattern']), codepoint)
for option in config.options(section):
# Go through each section's options. If it has _rep in it,
# It's a representation method. Add it to the lookup.
if re.search(rep_search, option):
has_a_rep = True
self.add_to_lookup(codepoint, section, option=option,
value=regnet.parse_regnet(list(config[section][option])))
if not has_a_rep:
self.add_to_lookup(codepoint, section)
Here’s how it works: abba creates a register of abbreviations that it reads
in from the ruleset. For each abbreviation, it dynamically assigns one of the
Unicode codepoints. First it associates that codepoint with the regexp (the
regnet, really—more on that later) belonging to that abbreviation. Then it adds
that codepoint to a lookup table containing that abbreviation’s
representations, whatever they happen to be. In both cases the codepoint acts
as a stand-in for the abbreviation object, but we are able to use all the
information encoded about the abbreviation without making any assumptions as to
its composition.
Regnet
The other half of abba is the Regnet format, which is a user-friendly way to
define abbreviation rules. Under the hood, abba uses regular expressions to
find letter sequences and replace them with codepoints. But I wanted to make
abba extensible, and regular expressions are not fun to write by anybody,
myself included. So I created a format called Regnet (which means ‘The Rain’ in
Swedish and is the first Swedish word beginning with “Re-” to be found
here). Regnet lets you take something like
the#iso and turn it into an object that maps (?<=\\\\b)\g<pat>(?=\\\\b)
onto ð with a precedence level of 0 (which means “the” will get abbreviated
before, say, terminal e). Here’s a sample of the ruleset for the New
Abbreviations in Regnet format:
[UN]
pattern: un
uni_rep: u${lin_low}
[R ROTUNDA]
pattern: (?<=[bdhmnopquw])r
uni_rep: {a75b}
[THE]
pattern: the#iso
uni_rep: ${th}
abba in Action
You put it together and you’re able to abbreviate texts in an extensible and generalizable manner. Here’s a sample text produced that models some (though not all) of the New Abbreviations’ rules:
Pꝛut, tut, ſa͞d Pãagrṷl, Ⱳt doð ðis fo̥l mean to ſay? I ðḭ h̭ is upon ð foꝛgi̫ of ſom̭ diabolical to̫ṷ, ⁊ ðt enchãer-lik̭ h̭ wo̬ld charm us. To Ⱳom oṋ of his men ſa͞d, Wiðo̬t do̬bt, ſir, ðis fe‖ow wo̬ld cõ̬erf̭͞t ð la̫uag̭ of ð Pariſians, but h̭ doð only flay ð Latin, imagini̫ by ſo do̫͞ ðt h̭ doð highly Piͫariz̭ it in moſt eloq̭̇̃ terms, ⁊ ſtro̫ly conc̭͞teð himſelf to b̭ ðrfoꝛ̭ a great oꝛatoꝛ in ð French, beca̬ſ̭ h̭ diſda͞neð ð common manner of ſpeaki̫. To Ⱳich Pãagrṷl ſa͞d, Is it trṷ? ð ſcholar anſwer̳, My woꝛſhipful loꝛd, my geni̭ is not apt naṱ to ðt Ⱳich ðis flagitio̬s nebulon ſa͞ð, to excoꝛiaṱ ð cut(ic)uḽ of o̬r vernacular Ga‖ic, but vic̭-verſa‖y I gnav̭ oper̭, ⁊ by veḽs ⁊ ram̭s eniṱ to locupletaṱ it WITH ð Latinicom̭ reduͫanc̭. By G—, ſa͞d Pãagrṷl, I wi‖ teach ỿ to ſpeak. But firſt com̭ hiðer, ⁊ te‖ m̃ Ⱳenc̭ ðo̬ art. To ðis ð ſcholar anſwer̳, ð pꝛimeval oꝛigin of my av̭s ⁊ atav̭s was iͫigenary of ð Lemovic regɸs, Ⱳr r̭q̇i̭ſceð ð coꝛpoꝛ of ð hagiotat ſt. Martial. I uͫerſtaͫ ð̭̭ very we‖, ſa͞d Pãagrṷl. Ⱳn a‖ com̭s to a‖, ðo̬ art a Limo̬ſin, ⁊ ðo̬ wilt her̭ by ðy aff̭ɥ̳ ſp̭̭ch cõ̬erf̭͞t ð Pariſians. We‖ now, com̭ hiðer, I muſt ſhow ð̭̭ a new trick, ⁊ haͫſomely giv̭ ð̭̭ ð combfeat. WITH ðis h̭ to̥k him by ð ðꝛoat, ſay̫͞ to him, ðo̬ flay̭ſt ð Latin; by ſt. John, I wi‖ mak̭ ð̭̭ flay ð fox, foꝛ I wi‖ now flay ð̭̭ aliv̭. ðn began ð po̥ꝛ Limo̬ſin to cry, Haw, gwid maaſter! haw, Laoꝛd, my halp, ⁊ ſt. Marſhaw! haw, I’m woꝛri̭d. Haw, my ðꝛoppḽ, ð bean of my cragg is bꝛuck! Haw, foꝛ ga̬ad’s ſeck lawt my lean, mawſter; waw, waw, waw. Now, ſa͞d Pãagrṷl, ðo̬ ſpeak̭ſt natuꝛa‖y, ⁊ ſo let him go, foꝛ ð po̥ꝛ Limo̬ſin had tota‖y bewꝛay̭d ⁊ ðoꝛo̬ghly conſhit his bꝛ̭̭ch̭s, Ⱳich wer̭ not ḓ̭p ⁊ larg̭ eno̬gh, but ro̬ͫ ſtra͞ght çnɸ̳ gregs, havi̫ in ð ſeat a pi̭c̭ lik̭ a k̭̭li̫’s ta͞l, ⁊ ðrfoꝛ̭ in French ca‖̳, ḓ cha̬ſſ̭s a q̭̬̭̇ ḓ merlus. ðn, ſa͞d Pãagrṷl, ſt. Alipãin, Ⱳt civet? Fi̭! to ð devil WITH ðis tuꝛnip-eater, as h̭ ſtḭs! ⁊ ſo let him go. But ðis hug of Pãagrṷl’s was ſuch a terroꝛ to him a‖ ð days of his lif̭, ⁊ to̥k ſuch ḓ̭p impꝛ̭ſſɸ in his fancy, ðt very often, diſtraɥ̳ WITH ſudden affrightm̭̃s, h̭ wo̬ld ſtartḽ ⁊ ſay ðt Pãagrṷl held him by ð neck. B̭ſiḓs ðt, it pꝛocuꝛ̳ him a cõinual dꝛo̬ght ⁊ ḓſir̭ to dꝛḭ, ſo ðt after ſom̭ few y̭ars h̭ di̭d of ð deað Rolaͫ, in pla͞n ̭̫liſh ca‖̳ ðirſt, a woꝛk of diviṋ v̭̫eanc̭, ſhowi̫ us ðt Ⱳich ſa͞ð ð philoſopher ⁊ A̬lus Ge‖i̬s, ðt it becomeð us to ſpeak accoꝛdi̫ to ð common la̫uag̭; ⁊ ðt w̃ ſho̬ld, as ſa͞d Oɥavian A̬guſtus, ſtriv̭ to ſhu̲ a‖ ſtra̫̭ ⁊ ṵnown terms WITH as much h̭̭dfulṋſs ⁊ circumſp̭ɥɸ as pilots of ſhips uſ̭ to avo͞d ð rocks ⁊ ba̰s in ð ſeaa͞d Pãagrṷl, Ⱳt doð ðis fo̥l mean to ſay? I ðḭ h̭ is upon ð foꝛgi̫ of ſom̭ diabolical to̫ṷ, ⁊ ðt enchãer-lik̭ h̭ wo̬ld charm us. To Ⱳom oṋ of his men ſa͞d, Wiðo̬t do̬bt, ſir, ðis fe‖ow wo̬ld cõ̬erf̭͞t ð la̫uag̭ of ð Pariſians, but h̭ doð only flay ð Latin, imagini̫ by ſo do̫͞ ðt h̭ doð highly Piͫariz̭ it in moſt eloq̭̇̃ terms, ⁊ ſtro̫ly conc̭͞teð himſelf to b̭ ðrfoꝛ̭ a great oꝛatoꝛ in ð French, beca̬ſ̭ h̭ diſda͞neð ð common manner of ſpeaki̫. To Ⱳich Pãagrṷl ſa͞d, Is it trṷ? ð ſcholar anſwer̳, My woꝛſhipful loꝛd, my geni̭ is not apt naṱ to ðt Ⱳich ðis flagitio̬s nebulon ſa͞ð, to excoꝛiaṱ ð cut(ic)uḽ of o̬r vernacular Ga‖ic, but vic̭-verſa‖y I gnav̭ oper̭, ⁊ by veḽs ⁊ ram̭s eniṱ to locupletaṱ it WITH ð Latinicom̭ reduͫanc̭. By G—, ſa͞d Pãagrṷl, I wi‖ teach ỿ to ſpeak. But firſt com̭ hiðer, ⁊ te‖ m̃ Ⱳenc̭ ðo̬ art. To ðis ð ſcholar anſwer̳, ð pꝛimeval oꝛigin of my av̭s ⁊ atav̭s was iͫigenary of ð Lemovic regɸs, Ⱳr r̭q̇i̭ſceð ð coꝛpoꝛ of ð hagiotat ſt. Martial. I uͫerſtaͫ ð̭̭ very we‖, ſa͞d Pãagrṷl. Ⱳn a‖ com̭s to a‖, ðo̬ art a Limo̬ſin, ⁊ ðo̬ wilt her̭ by ðy aff̭ɥ̳ ſp̭̭ch cõ̬erf̭͞t ð Pariſians. We‖ now, com̭ hiðer, I muſt ſhow ð̭̭ a new trick, ⁊ haͫſomely giv̭ ð̭̭ ð combfeat. WITH ðis h̭ to̥k him by ð ðꝛoat, ſay̫͞ to him, ðo̬ flay̭ſt ð Latin; by ſt. John, I wi‖ mak̭ ð̭̭ flay ð fox, foꝛ I wi‖ now flay ð̭̭ aliv̭. ðn began ð po̥ꝛ Limo̬ſin to cry, Haw, gwid maaſter! haw, Laoꝛd, my halp, ⁊ ſt. Marſhaw! haw, I’m woꝛri̭d. Haw, my ðꝛoppḽ, ð bean of my cragg is bꝛuck! Haw, foꝛ ga̬ad’s ſeck lawt my lean, mawſter; waw, waw, waw. Now, ſa͞d Pãagrṷl, ðo̬ ſpeak̭ſt natuꝛa‖y, ⁊ ſo let him go, foꝛ ð po̥ꝛ Limo̬ſin had tota‖y bewꝛay̭d ⁊ ðoꝛo̬ghly conſhit his bꝛ̭̭ch̭s, Ⱳich wer̭ not ḓ̭p ⁊ larg̭ eno̬gh, but ro̬ͫ ſtra͞ght çnɸ̳ gregs, havi̫ in ð ſeat a pi̭c̭ lik̭ a k̭̭li̫’s ta͞l, ⁊ ðrfoꝛ̭ in French ca‖̳, ḓ cha̬ſſ̭s a q̭̬̭̇ ḓ merlus. ðn, ſa͞d Pãagrṷl, ſt. Alipãin, Ⱳt civet? Fi̭! to ð devil WITH ðis tuꝛnip-eater, as h̭ ſtḭs! ⁊ ſo let him go. But ðis hug of Pãagrṷl’s was ſuch a terroꝛ to him a‖ ð days of his lif̭, ⁊ to̥k ſuch ḓ̭p impꝛ̭ſſɸ in his fancy, ðt very often, diſtraɥ̳ WITH ſudden affrightm̭̃s, h̭ wo̬ld ſtartḽ ⁊ ſay ðt Pãagrṷl held him by ð neck. B̭ſiḓs ðt, it pꝛocuꝛ̳ him a cõinual dꝛo̬ght ⁊ ḓſir̭ to dꝛḭ, ſo ðt after ſom̭ few y̭ars h̭ di̭d of ð deað Rolaͫ, in pla͞n ̭̫liſh ca‖̳ ðirſt, a woꝛk of diviṋ v̭̫eanc̭, ſhowi̫ us ðt Ⱳich ſa͞ð ð philoſopher ⁊ A̬lus Ge‖i̬s, ðt it becomeð us to ſpeak accoꝛdi̫ to ð common la̫uag̭; ⁊ ðt w̃ ſho̬ld, as ſa͞d Oɥavian A̬guſtus, ſtriv̭ to ſhu̲ a‖ ſtra̫̭ ⁊ ṵnown terms WITH as much h̭̭dfulṋſs ⁊ circumſp̭ɥɸ as pilots of ſhips uſ̭ to avo͞d ð rocks ⁊ ba̰s in ð ſea.
Three Shorthands
2019-11-23
I The New Abbreviations
Thus far I’ve designed and used three shorthands. The first was an alphabetic, orthographic shorthand, which I’ve written about in more detail elsewhere: The New Abbreviations. It originated as a project to correct my handwriting, which was crabbed, ugly, and above all, inconsistent.
It ended around 2017. Ultimately, I hit the limit of what you could do as long as you insisted on block lettering and preserving spelling exactly; the character set continued to increase in size as I came up with new glyphs to abbreviate certain combinations. At an aesthetic level, my one-time aversion to cursive had dissipated over the years; I was more interested in cursive forms (at the above link, you can compare the first image with the second to see how my own writing grew more cursive) and thus more tolerant of those schools of proper shorthand.
Having not set out to learn shorthand, after all, I had never had much motivation to learn a whole shorthand system. But my interest in other forms started percolating a little and so I decided to look around at what there was.
II Forkner/F-Minus
The two most famous shorthand systems are Gregg and Pitman. They have a lot in common, and what they have in common is largely representative of shorthands as a whole. They are phonemic/phonetic, rather than orthographic, designed to encode spoken word sounds rather than spellings.

This was a quality I had decisively opted out of when writing the New Abbreviations; it’s tremendously easier to reconstruct a word by spelling it out than by approximating its sounds and working backwards from there. And indeed, systems like this are much more demanding in terms of reading back. Nevertheless, you can compress quite a bit in terms of strokes and time if you ignore English’s famously crufty spelling and go straight to the sounds.
They are also non-alphabetic: they opt for simpler forms which are also more compressed than the Latin or any other alphabet. As a rule this makes them harder to read and write, again: your existing understanding of how to read and write will be of no use to you.
It also has the side effect of giving them an extremely low tolerance for variation. They are composed of extremely simple forms—mostly loops and curves—so in order to achieve the required diversity for representing the phoneme inventory of English as well as the standalone abbreviations for common words and phrases, relatively subtle variations on these forms will have significantly different semantics.
It was some of the above drawbacks, or at least learning-curve factors, which led me to adopt a ‘softer-core’ system: the alphabetic Forkner shorthand. Forkner begins with ordinary, cursive, longhand writing, and then replaces the letters with strokes and shapes representing sounds.

The resulting system is vastly less efficient that Pitman or Gregg, but much easier to learn. Easier to write, as you can use normal longhand as a basis and insert what you know.
I did end up changing it a bit to suit my own needs; that’s the version I call F-Minus. Some of the changes are relatively minor: for instance, the painstaking representation of vowels with curly apostrophes and commas seems completely unnecessary, so rather soon on those got straightened out into ticks when I was writing them. I also almost never combine multiple small words (qv. “may be able”, above) into a single outline; I find them very difficult to decipher and of fairly limited utility.
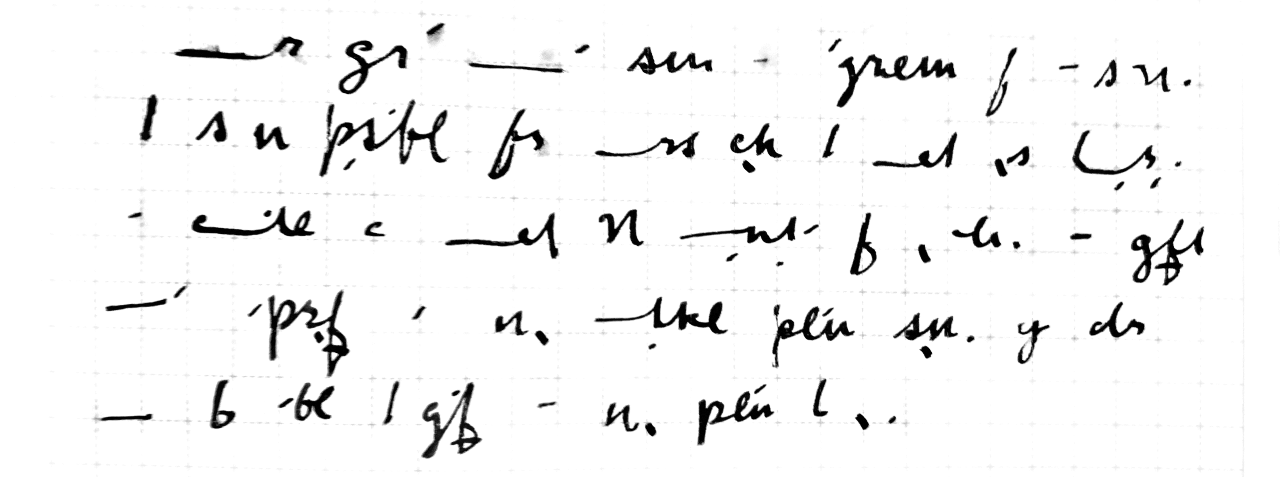
Some other changes were more substantive. The primary complaint I have with Forkner is that which it doesn’t bother to remove from longhand script. In particular, those parts of script which are more burdensome to write because as letters they don’t flow together particularly nicely.
You can think specifically of those lowercase letters which begin in the upper-right corner of the box1. Letters like c and d are fine to start off a word with, when you’re not traveling from the left, but awkward to connect to, as you must cross the body of the letter before starting it. I felt that they were actually the slowest and clumsiest part of my writing; thus I actually stopped using them in favor of more superficially complex letters, or existing ones with diacritics (k in the first case, and ṭ in the second). The combining dot below, as in the second example, ended up getting a fair bit of use. d became ṭ, ch became ɟ, v became ƒ̱. Putting a dot below a letter (or crossing a descender) becomes a kind of voicedness toggle on that letter.
With the changes came some slightly more involved rules about stroke choice. For instance, as mentioned above, letters like c and d are only clumsy when they don’t begin a word. So in F-Minus, you still use them if a word begins, for instance, with /k/. This minor optimization is also necessary to preserve the existing Forkner semantics of k, which is used to abbreviate the prefix contr-. Since we can assume we’ll only ever encounter that at the beginning of word, it’s safe to introduce the medial and final use of k as above without worrying that we’re introducing too much ambiguity.
III Something New
Learning Forkner, and then customizing it to my liking, certainly kept an awareness of Gregg, Pitman, and their varsity-level analogs in my mind. I suppose it was only a matter of time before I decided to take another swing at one, which happened only a few months ago.
I will confess that swing was unsuccessful. I decided I would learn Pitman; I think that’s partially because I liked the aesthetics better, but also because I was still wary of the error tolerance of the script.
As mentioned before: the simpler the forms, the lower the natural sign inventory, and thus the more subtle variations such as line width are depended on to represent different signs. Even at the best of times, and even after my self-training with the New Abbreviations, I don’t trust that I have the most consistent writing in the world. And given that I often write on the subway or the like, I’m aware that I am not going to have perfect motor control.
Between the two, then, I opted for Pitman; Pitman uses variations in line width to discriminate between signs, meaning that it has a wider graphical inventory than Gregg, and thus is hopefully more error-tolerant.
Error-tolerant it might be, but it’s still extraordinarily complicated. Moreover, I had never had to learn anything from scratch before which didn’t relate to what I already knew. So it was difficult to associate the still-subtly-varying curves of Pitman with their different sounds without a lot of rote memorization, which I simply didn’t have in me.
On the other hand—I’ve never had to write in any of these shorthands for another person. I’ve always been a speaker (or writer) population of 1. Which means, why not just make another one up myself? It’s a lot easier for me to remember something I came up with than something I read out of a book. And this way I could try to optimize for the qualities I find most important, especially that concept of error tolerance.
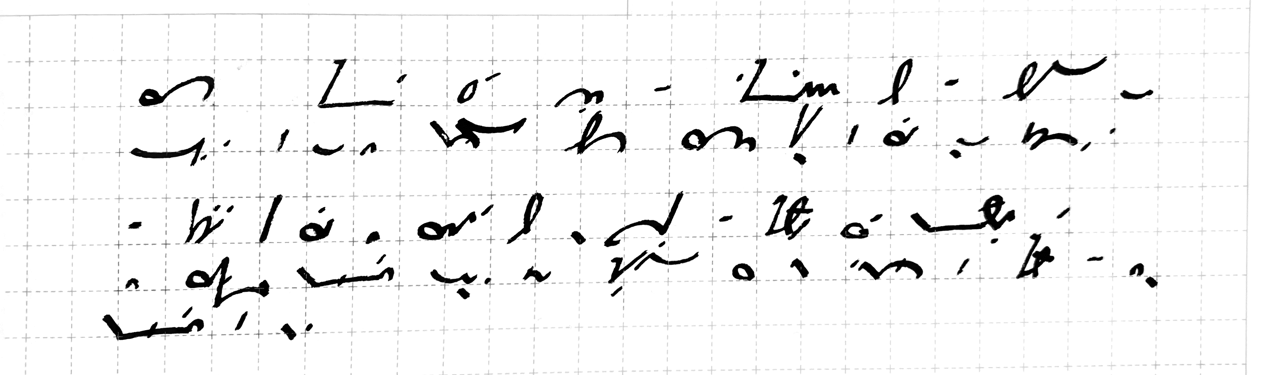
So for the last couple of months I’ve been putting together a Gregg/Pitman-style system for myself. The first thing to know is that it takes directly from Forkner/F-Minus wherever there’s nothing to improve. For instance: this system, like many others, focusses on the consonants in a word and leaves out the vowel sounds, or has them added as diacritics if required. The values for those diacritics are generally take directly from Forkner. So ′ above the stroke stands for a, whereas ′ below the stroke stands for o, and ` below the stroke stands for u.
The second thing to know is that the qualities being optimized for here are the same ones that led me to adjust Forkner to my liking and to shy away from Pitman and Gregg: ergonomics and error-tolerance. In contrast to the general assumption behind those and many other systems, that the most ergonomic strokes are those which underpin cursive handwriting, and that the strokes which underpin cursive handwriting are loops and curves, I’ve found that I have much better luck holding a steady line if I can alternate my curves with straight lines and acute angles. It’s in the oblique angles, along with one curve having to seamlessly turn into another, that my error rate goes up and the distinctiveness of the lines is most imperiled.
For those purposes I’ve made a couple general design decisions: I’ll minimize the meaningful variation within a stroke kind (at the expense of more writing, no doubt), and I’ll try to promote clear angles between strokes. For instance: instead of the 10 curving strokes that I count in the basic Gregg inventory, in my new system there are 2: long and short. In the realm of straight lines we allow ourselves slightly more extravagance, with 4 (to Gregg’s 9): NW/SE-oriented in long and short, NE/SW-oriented in long and short.

We extend this meager inventory predictably, with the vocalizing hatch mark that already showed up in F-Minus. So a short curve is /s/ and a long one is /r/, while putting a notch in that curve (or a little serif if the curve begins or ends an outline) makes /z/ and /l/, respectively. Similar schemes obtain for the lines: /k/ & /g/, /t/ & /d/, /ch/ & /j/, /p/ & /b/.
What’s important, and what determines a lot of the rest of the strokes that complement that basic scheme, is that every stroke have a vertical orientation; that is, it always be rendered “going up” or “going down”. That’s because the one true formal innovation (as far as I’m aware) of this system is how it treats blends, or consonant clusters.
So far I’ve been inclined to keep to a minimum those strokes which stand for common consonant sequences, as oppose to individual sounds. This is largely because of my self-imposed parsimony of strokes. I simply don’t have the solution space to apportion a separate kind of curve to /st/ or /nd/. However, one method that I have come upon of designating a consonant sequence without an intervening vowel—should it appear internal to a syllable or at a syllable boundary—is to control the relative orientation of the following stroke.
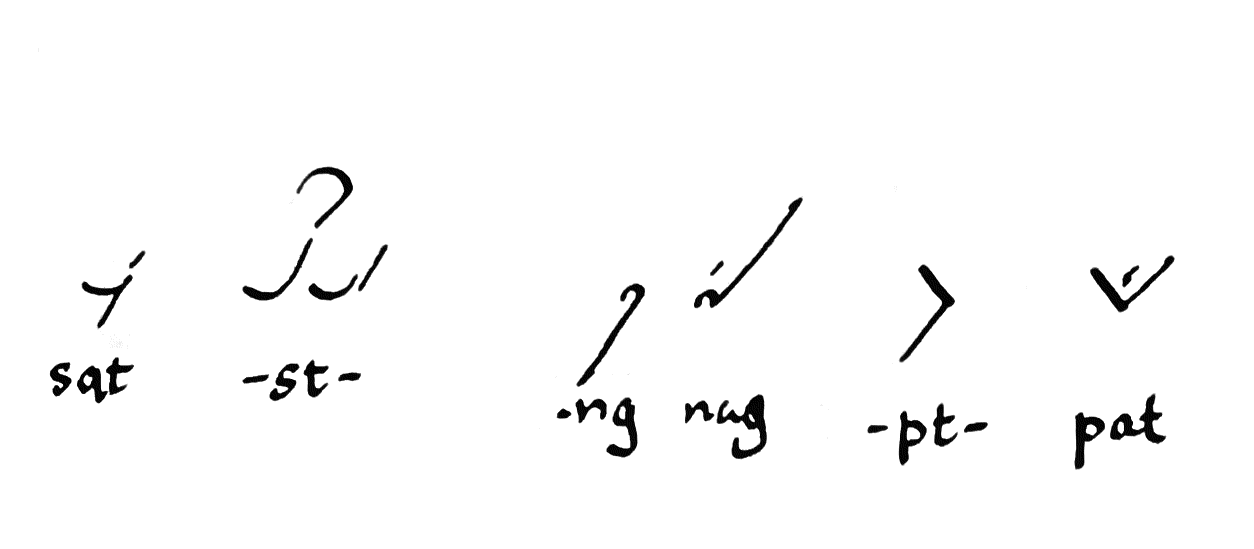
I’ll give an example: let’s say you have an s followed by a t, as mentioned above. That will be a short stroke followed by a short, NE/SW line. As a matter of fact, there are two ways to write each one of those strokes. The s can be a smile or a frown (so to speak), and then if you follow on with a t it can proceed up and to the right, or down and to the left. In this case, if this is beginning of a word, the choice of s is entirely arbitrary. Smile and frown are equivalent in meaning. But if you choose a smile, then we must pay attention to the orientation of the right side of that stroke. It’s pointing upwards. Now we have a semantics of blends: if you want represent st without anything in the middle, you continue the vertical orientation, and write a short straight line going up and to the right. If, on the other hand, you want to represent sVt, with some intervening vowel in the middle (sat, sit, set, soot, …), then you reverse vertical orientation, turning down and to the left.
Thus, every stroke in the system is always clearly pointing up or down.
This does a couple things for the system. First, if we assume that consonants are more often found on their own than in blends, it optimizes for the presence of acute angles between strokes, which is easier to read and write. Second is that it actually communicates a little bit more than what I know about systems like Gregg and Pitman (here I could easily be ignorant of something), in that even without adding a vowel diacritic, we can visually distinguish between CC and CVC. This—it is to be hoped—makes it more likely that an outline without any vowels will still be unambiguous, or indeed an outline where we haven’t bothered to differentiate between voiced and unvoiced.
There remain lots of edges to sand off. It remains to be seen how much
of and which of the Forkner word, prefix or suffix abbreviations can and
should be pirated wholesale into this system. Certain additional rules
and shortcuts are needed in order to, for instance, make it as easy and
forgiving to write and read a blend like the aforementioned upward s-t,
where both the horizontal and vertical orientation are the same, such
there’s no angle to differentiate between strokes. And it might be that
clever stroke design is not sufficient to avoid it being too onerous
to write certain long consonant sequences. And it’s certainly much
more demanding in memorization than Forkner or its modifications; I’m
still thinking my way through each outline. If that never accelerates,
of course, it will be interesting at best but entirely useless. It’s important to note that I’m left-handed and that fact has
significantly impacted the ergonomics of all of my writing. There are
letters and shapes which might be very uncomfortable for me but quite
normal for a right-handed person, and vice versa; thus I make no claims
for the universality of my ergonomic preferences. ↩
A Curriculum of Current Phonetic Shorthand
2020-04-05
Henry Sweet’s Current Shorthand1 is a historical curiosity twice over: once because very few people today need to learn shorthand at all or even know what it is; twice because as shorthands go, it’s completely obscure. I learned about it because the surprisingly active and enjoyable Shorthand Subreddit is populated by people who seem to really enjoy spelunking in digital archives for self-published books from the late 19th century, the heyday of shorthand, when there was actual money in designing and publicising a shorthand system of one’s own.
Nevertheless, insofar as one is already interested in learning a shorthand2, it’s quite worth taking a look at. I think it has a combination of qualities that make it very recommendable:
- it is efficient, compressing quite a bit of writing into a small number of strokes;
- it is (relatively) cursive, visually and mechanically resembling longhand writing more than simple ellipses or geometrical shapes;
- by means of the second fact, it is, visually, fairly resistent to ambiguity (I’ve talked about this before).
It’s also got some marks against it. In addition to being very complex (or at least involved, or at least deep), it is doubly inaccessible: once because the only extant text that I know about is a scanned PDF of Sweet’s own handwritten (!) manual from 1892, and twice due to the fact that the manual is, frankly, not well-laid out.
Part of it is that Sweet was a phonetician before phonetics was a thing; his vocabulary around different sounds is not the same as we would use. More difficult is that the signs are actually quite systematic but Sweet often leaves the system implicit; there are a few places that his choice of symbol names in fact obscures their relationships to other symbols.
I’d like to try to lay out some of the same information contained in the manual in a more systematic and searchable way. Let’s see if it works out.
Some preliminary remarks
Like other phonetic shorthands, the basic principle of Current is to represent spoken or written language with a sequence of written symbols. The symbols are more numerous, and each one simpler, than the letters of the alphabet, so that more can be written, more quickly, than if you spelled the equivalent language out. The symbols making up a single word (or sometimes group of words) are written together, without taking the pen off the page (as in cursive writing), as that speeds things up as well.
Generally speaking, especially at first, Current can be approached word-by-word. And since we’re dealing with the phonetic variant, the outline for a word can be the symbols for all of its sounds written together.
Finally, to write more quickly, a number of other techniques will be used. These include:
- leaving out certain sounds;
- using distinct symbols for common sequences of more than one sound;
- using distinct symbols for common words.
We’ll start with the most basic part of the symbol inventory: the symbols that make up the basic sounds of spoken English3. Anyone who knows them all will be able write (and read back) any English whatsoever; everything that comes afterwards will simply make the process of writing more efficient.
The basic sounds can, of course, be divided into consonants and vowels.
Consonants
Consonants, generally, are represented by full-letter-sized symbols.
Heights
Full symbols have four heights:
- short, as in the height of a lower-case
x; - high, as in the height of a lower-case
lor upper-caseI; - low, as in the height of a lower-case
y; - tall, which extends from the top of an
lto the bottom of ay.4
Stroke Consonants
The atom of current shorthand is the connected vertical downstroke. Because Current mimics normal handwriting, it’s pretty tolerant of different degrees of slant, so “vertical” here is a relative rather than absolute term.
A vertical stroke is connected by the upward stroke that leads into it and the upward stroke that leads from it. There are two ways to connect into those strokes: with a curve, and with a sharp angle.
\[2 \text{ points of connection} × 2 \text{ ways to connect} = 4 \text{ styles of stroke:}\]
| starting from an angle | starting from a curve | |
|---|---|---|
| leading into an angle |  |  |
| leading into a curve | 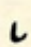 | 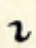 |
Constructing a matrix of heights and styles gives us the most basic strokes.
\[4 \text{ styles of stroke} × 4 \text{ heights} = 16 \text{ strokes:}\]
| stroke | curve-stroke | stroke-curve | curve-stroke-curve | |
|---|---|---|---|---|
| short | t | d | n | r |
| high |  p p | 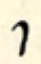 b b | 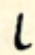 m m | 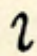 kw kw |
| low |  k k | 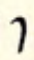 g g |  ng ng | 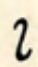 ly ly |
| tall |  tsh tsh | 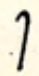 dzh dzh |  ny ny | 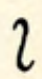 ry ry |
Arranged thus it’s hopefully evident that there’s an order to what sign goes with what sound. Sweet is particularly hot on the correspondence between where in the mouth a sound is articulated and where it’s placed, vertically, on the page (the man was a phonetician), which I think is less helpful; however, especially in the upper-left of the matrix, it hangs together ok.
The basic strokes stand for unvoiced sounds, and the curve-strokes stand for their voiced counterparts. It’s hopefully useful and intuitive that /t/ goes with /d/, /k/ with /g/, and so forth.
Similarly, /tsh/ (usually written “ch”, like “cheer” and “cheek”) and /dzh/ (one of the sounds made by “g” or “j”, as in “George”) go together.
The third column is the nasals; in English there isn’t a voiced/unvoiced distinction for them.
The fourth column hangs together less cleanly. A short curve-stroke-curve stands for /r/, which is obviously very common in English; the rest of the column is left over for certain consonants followed by glide vowels.
So we can give a rough phonetic reading of the same matrix:
| unvoiced | voiced | nasal | liquid | |
|---|---|---|---|---|
| dental | t | d | n | r |
| labial | p | b | m | kw |
| velar | k | g | ng | ly |
| palatal | tsh | dzh | ny | ry |
Loop Consonants
The second basic element of the vocabulary is the loop, which as a term is hopefully self-explanatory.
Loops can have the same heights as strokes; however, there are only two types of loop:
- regular, where the pen starts from the bottom-left, forms a loop,
and continues to the bottom-right:
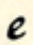
- inverted, where the pen starts from the upper-left,
forms a loop downwards, and continues to the upper-right:
\[2 \text{ styles of loop} × 4 \text{ heights} = 8 \text{ loops:}\]
| loop | inverted loop | |
|---|---|---|
| short | s | z |
| high |  f f | 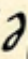 v v |
| low | 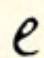 zh zh | 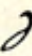 sh sh |
| tall | 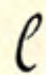 nzh nzh | 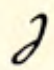 nsh nsh |
The loops are used for what Sweet calls hiss sounds but what we’d call fricatives, and mostly sibilants. The voiced/unvoiced relationship of orientation is in place, which is very helpful.
Less helpful is the fact that it swaps midway through. In the first two rows, the left side is unvoiced and the right side is voiced. In the bottom two, we swap over. Sweet’s rationale for this is that /sh/ is more common, and that the low inverted loop is easier to write. I’m sure he’s right, but I don’t know if it’s worth the added cognitive load.
The tall loops are left for blends involving /n/ + /the sound made by their low counterparts/. These are more useful than they seem at first glance, since in practice /nsh/ also works for /ntsh/ (as in “inch”) and /nzh/ also works for /ndzh/ (as in “change”).
Rings
We’ve covered nearly all the consonants under the above two theories, but there are a few stragglers that don’t fit neatly.
The “canonical” form of /h/, so to speak, is an elongated low ring.
There are two sounds, voiced /th/ and unvoiced /dh/, represented by “th”. They are both short.
All three are written starting from the top.
| ring | half ring | |
|---|---|---|
| short | 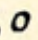 th th | 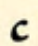 dh dh |
| low | 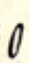 h h |
It’s important to note, however, that /h/ is much more commonly written
as a long diagonal stroke beginning below the line of writing, like so:

Semivowels
The semivowels (or glides) are both written with what Sweet calls the
“flat curve”: 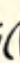
These are also started from the top.
| flat curve | |
|---|---|
| high | 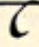 w w |
| low | y |
As we’ve already seen, though, there are some blends with /w/ and /y/ that are useful to know as these symbols are a bit awkward to write in the middle of a word.
Wave
The final consonant to cover is /l/, which is written with a “wave”, or what
we might now call a tilde:  . It’s hard
to classify it by height, though I suppose technically it’s short. But
in reality it’s the only consonant whose overall height is less than
that of an
. It’s hard
to classify it by height, though I suppose technically it’s short. But
in reality it’s the only consonant whose overall height is less than
that of an x.
One result of this is that it can be comfortably written on the line
or at around x height. The former generally is used when /l/ is not
preceded by a vowel, while the latter is generally used when it is.
Vowels
The vowels of Current are… numerous. The principle of their general
use is the same as most other phonetic shorthands: in writing, leave
them out whenever possible. A word written like fnctshn or cmptr
is often completely intelligible, especially written in context.
This principle is particularly important in light of one of Sweet’s basic principles of writing vowels: “medially, all weak vowels are expressed by the stroke.” That is, the short upward connecting stroke between two consonants should be the standard way of representing an unstressed vowel in the middle of a word.
This is perfectly sensible and more-or-less the default, as I say; however, some of the more finicky elements of the shorthand arise when Sweet tries to ensure that principle’s inverse: the presence of a short, connecting stroke should imply the presence of an unstressed vowel in the middle of a word. This would require that we strictly draw two consonants without any intervening stroke if there’s no vowel (or otherwise use a consonant blend, which are very plentiful and pretty crucial in practice). I say good luck: in order to make your outlines intelligible, you’ll sometimes have to have some space between two consonants even if there’s no vowel between them. Don’t sweat it.
This is an area where there won’t be a very satisfactory way of representing the sounds: Sweet’s notation for vowels is pretty straightforward but archaic; but then again, it’s not very practical to require the interested reader to know IPA as well. I’m going to try to represent them with words that obviously demonstrate them, after John C. Wells.
Positions
While consonants are some kind of letter-form of at least x height,
vowels are generally smaller: roughly half x-height. Ordinarily,
all vowels live within the x space, and therefore have two positions:
- “low-mid”, which sits at the baseline of writing:
 ;
; - “high-mid”, which sits at the top of the
x: .
.
Hooks
The most basic form of vowel sign is the hook, which is just a single
horizontal curve: .
Hooks have two orientations:
- up, with the two ends of the curve pointing up:
- down, with the two ends of the curve pointing down:

Hooks have two lengths:
- short, about half the width of an
x: - long, about the full width of an
x(or longer, as is useful):
Generally speaking, the long versions of the symbols are the “longer” of the pair.
\[2 \text{ positions} × 2 \text{ orientations} × 2 \text{ lengths} = 8 \text{ hooks:}\]
low-mid hooks
| hook | long hook | |
|---|---|---|
| up | PRICE5 |  PALM PALM |
| down |  TRAP TRAP |
high-mid hooks
| hook | long hook | |
|---|---|---|
| up | KIT5 | FLEECE5 |
| down | DRESS6 |  FACE6 FACE6 |
Double Hooks
Double hooks can vary along all the same dimensions as single hooks; they just consist of two curves written together.
\[2 \text{ positions} × 2 \text{ orientations} × 2 \text{ lengths} = 8 \text{ double hooks:}\]
low-mid double hooks
| double | long double | |
|---|---|---|
| up |  FOOT FOOT |  GOOSE GOOSE |
| down | 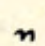 POOR POOR |
high-mid double hooks
| double hook | long double hook | |
|---|---|---|
| up | 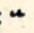 UNITE UNITE | 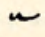 USE USE |
| down |  FUEL FUEL |
Both the down and the high-mid versions deserve a little explanation:
- double down-hooks represent the same sound as their up-hook counterparts, but with a schwa /ə/ at the end.7
- high-mid double hooks represent a /u/ sound, just like the low-mid ones, but with a /y/ in front.
The distinction between the short /yu/, like the first vowel in “unite”, and the long /yuu/, like the vowel in “use”, is often subtle enough to be disregarded when writing.
Vowel loops
The next class of vowel symbol is the (little) loop. It’s about the size of an up- or down-hook; however, instead of a horizontal curve it’s a completed circle.
Just as with their full-size consontantal counterparts, loops can be regular or inverted. To help distinguish them from the bigger versions we will say:
- up, where the pen starts from the bottom-left, forms a loop,
and continues to the bottom-right:
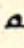
- down, where the pen starts from the upper-left,
forms a loop downwards, and continues to the upper-right:

If a loop is the first symbol in an outline, we need to be able to
distinguish up from down since obviously there will be no connecting
stroke to connect from. Therefore up loops are
not closed if they’re the first part of any outline:
 . This principle will
hold for any of the up-loop variants.
. This principle will
hold for any of the up-loop variants.
\[2 \text{ positions} × 2 \text{ orientations} × 2 \text{ lengths} = 8 \text{ loops:}\]
low-mid loops
| loop | long loop | |
|---|---|---|
| up |  MOUTH5 MOUTH5 |  GOAT5 GOAT5 |
| down |  STRUT STRUT |  SQUARE SQUARE |
high-mid loops
| loop | long loop | |
|---|---|---|
| up | CLOTH5 |  THOUGHT5 THOUGHT5 |
| down | A(ROUND)6 |  NURSE NURSE |
To come: Arbitraries, Consonant Groups, Rising Consonants, Finals, Implied Characters, Contraction, Word Omission, Limbs, Signs
The foregoing, insofar as curricula go, is demonstrably not much of a curriculum at all. For one thing, there are no samples of full outlines at all. This document is at very best a supplement to Sweet’s original manual. Hopefully it presents a more systematic introduction to the core elements, which are themselves the most systematic of the overall theory.
Needless to say, there are many elements in the latter part of the section that are arranged systematically and demonstrate productive principles (rather than just being bags of arbitrarily drawn words). In time I hope to get those together too.
this article has been amended based on feedback from the kind folks at r/shorthand. Current comprises two separate but simpilar systems: Orthographic,
which represents spelling; and Phonetic, which represents sound. I
think that he imagined a practitioner would learn both. I haven’t, and I
don’t think you need to either. I learned Phonetic; an interested reader
can probably choose either one. ↩ I will assume in this article that the reader has already passed that threshold. ↩ It’s at this point that an uncomfortable truth must be outed:
Sweet was English, spoke in Received Pronunciation, and designed his
system to reflect that fact. This is particularly pertinent when it comes
to the vowels: in RP British English, of course, “r” after a vowel is
usually not pronounced as a consonant. Sometimes it is omitted entirely;
sometimes it lengthens a preceding /a/ into PALM vowel; sometimes it’s
realized as a schwa. Current reflects this fact and, frankly, is at its best from a
phonetic perspective when the phonetics in question are RP rather than
American. As an example: it’s quite awkward indeed to write an /r/
sound after most vowels. It’s easier by far to write out how it would
sound in your best British accent. In practice, this becomes quite
natural. ↩ tall is a bad name, unnecessarily confusable with
high. Full would be more appropriate. ↩ Any of these vowels can have a small up-loop
added after them, without any ambiguity, to indicate that vowel followed
by a schwa. This, along with the special double-down-hook forms for the
/u/ vowels, provides a way to follow every possible vowel by a schwa. The utility of this is a little more obvious in light of the fact that the
phonetics in question is British Received Pronunciation. In nearly every
occasion that one would follow a vowel by an “r”—examples Sweet gives
include “carrier”, “career”, shower”, “follower”—it would be realized
in pronunciation as a schwa. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8 The DRESS, FACE, and schwa vowels, in particular, are usually
not necessary to write out with their full canonical symbols. The DRESS
and schwa vowels can usually be written with the short stroke, and the
long stroke, written from the baseline (as opposed from below it),
is a more convenient synonym for the FACE vowel. These symbols only
usually come into play when used in contractions or word signs. ↩ ↩2 ↩3 This, along with the 5 vowels, completes an inventory
of vowels followed by a schwa. This is, as previously noted, particularly
important in a phonetic system based on Received Pronunciation, where
segments that an American would pronounce as the r-colored vowel /ɚ/
or as a schwa followed by an r /ər/ would instead be pronounced as a
bare schwa /ə/. ↩
Smith Shorthand
2024-10-05
In late 2019, I wrote about a new shorthand system I was designing. Less than six months later it was in the bin, neither fully developed, nor learned, nor used. Instead I embarked on four-or-so happy years of consistent use of Henry Sweet’s Current Phonetic Shorthand, which was my regular choice for any and all note-taking.
A few times over that period I tried to learn Oliver’s Stenoscript, purely for fun: there were a few qualities it had that weren’t present in Current and which I wanted to try my hand at.
Stenoscript never stuck. There are some things I like about it but I find it basically too fiddly: there are too many distinctions that are meaningful in its signal space but far too fine for me to comfortably make when writing by hand.
Designing a shorthand, or a writing system of any kind, is quite like designing a programming language, in this way. The trick is to encode your signal as densely as possible—but not denser, as the adage goes. It’s trivial to make up maximally efficient encoding systems; but a shorthand needs to be simple and regular enough to be learned by heart, it needs to be made up of strokes that are comfortable for the human hand to write, and it needs not to be so densely encoded that natural variations and discrepencies result in dramatically different meanings.
Nevertheless, I conceived the certainly counterproductive idea to once again design my own shorthand—this time inspired by those parts of Stenoscript that I did like.
And this time I had rather more experience under my belt; Current and Stenoscript are far more extensive and expressive than Forkner, and the new system would be directly informed by what had worked for me and what hadn’t in those systems.
I’ve been at this for about two months. I have completely cannibalized my acquaintance with Current: I no longer really remember it, nor am I nearly as quick in the new system as I was in the previous. Nevertheless, there’s the pleasure of creation.
It would be absurd to claim that my new system is some kind of improvement over what exists, or even what I already knew. I would have been perfectly fine with what I already knew, and anyone who wants to take notes quickly by hand would be just as well-suited by what’s already known and practiced. But this is a well-designed system, I think, in that I was able to take those qualities that I wanted to explore and build something effective, attractive, well-structured and balanced around them. So it’s an aesthetic success. As an artwork (however limited its appeal might be), it’s a success.
Enough of a success that I’ve put my own name on it: I call it Smith Shorthand.
Stolze-Smith
2026-01-02
I recently spent about a year developing my own shorthand: Smith Shorthand. It was a success; the result hung together well and I’ve been a happy user since then.
In November, unbidden, came to me the sudden question: what would Smith look like if I had decided to keep the positional vowel system that I had discarded from its immediate inspiration, Oliver’s Stenoscript?
I didn’t have a particular appetite to overhaul and relearn my shorthand, but the short sketch I made was satisfying, and made me want to think about it more. Moreover, having gone to the core of it and retooled it, the full system now felt unwieldy and overengineered. So I decided I’d like to take this new altered core and evolve it into something much smaller and simpler than Smith.
The successor system is called Stolze-Smith (the name is a slant reference to another member of the Germanic family). As intended, it’s smaller than its predecessor. Even to the extent that it could theoretically fit in an Arthur Whitney-style reference card—though realistically an interested party should read the manual.
A significant change in my working habits since I was working on Smith: I’m an AI user now. In September I started learning to properly program with LLM-backed coding agents, having been in management for the couple of years prior, and not done much coding as a result. But since September I’ve been doing as much programming as I can, and almost always with Claude.
So it didn’t feel very far-fetched to start a new git repo when I wanted to build something new. The first thing I did after I decided that I’d like to make a proper system out of the incunabulum in my notebook was to encode the whole thing in JSON.
Having made structured data out of the rules I had sketched out, I was able to use Claude to iterate on the system. In principle this is not unlike iterating on source code. In fact, just as Claude is relatively knowledgeable about programming techniques and patterns, it knows enough about phonology and English phonotactics to be dangerous. The first design decision I had to make that didn’t follow completely from my starting principles was what to do with the sound /h/: I explained my problem and what considerations were most important to me, and Claude was able to make a suggestion (that I hadn’t thought of) that I liked enough to use.
Part of the advantage here is the same as rubber-ducking. To be effective with a coding agent you have to be structured, explicit and unambiguous in your problem definition, and that itself is a wonderful tool for finding a solution. But this rubber duck will also talk back.
An outcome that feels more significant, though, is:
Designing a shorthand is not a problem of computation, but it is a member of the truly massive set of non-computational problems that are amenable to computational prostheses. The gap between most of these problems and a computational prosthesis is usually: the problem is too recherché, not generalizable enough, of interest to too few people, and not remunerative enough to justify the time and energy necessary to write the software that would help you solve it.
The economics of such problems have been permanently altered.
Brief Assignment
Stolze-Smith, like its predecessor, possesses a set of briefs: these are the relation between a single sign, written by itself, and a common word. They’re single-sign abbreviations.
When you come up with your set of briefs, you have a series of criteria which you’d like to satisfy, none of which can be satisfied perfectly:
- you want to create abbreviations for the most common words;
- you want to maximize the compression of the briefs by abbreviating longer words rather than shorter;
- you want to assign words to phonetically appropriate signs: ideally the word begins with the sound the sign stands for, but if it doesn’t, it’s better that the word end with that sound rather than lack it altogether;
- you want neighboring signs to stand for similar words. For instance, if some sign stands for the word “this”, then it’s beneficial if the sign for “these” is graphically similar to the first one.
These can’t all be perfectly satisfied. For instance: when we consider assigning words to signs by sound (it’s better to assign “to” to the sign for /t/ than to the sign for /f/), we encounter the difficulty that the sounds for our signs are evenly distributed–there are two possible assignments per sound–but the set of the first sounds of the most common words in written English is not evenly distributed. Some sounds are overrepresented and some are underrepresented.
In fact, what we have here is an NP-hard combinatorial optimization problem. We can use computers to solve it. First we must express all of the above considerations as scoring functions which, given some set of assignments, combine into an overall score. The set of assignments that produces the highest score is the one that best balances all of these different considerations.
Even then, though: there are far too many sets of possible assignments to simply score them all. There is a branch of software that can help you find an optimal set of assignments, operations research (specifically, the subfield of integer optimization), but in the past, setting up an integer programming solver to solve such a problem has both been labor-intensive and required a fair amount of specialist knowledge.
Claude is exquisitely well-suited to fulfilling complex, well-defined API signatures. In the course of designing Stolze-Smith, I instantiated an OR-Tools solver with a comprehensive articulation of every facet of my intuition about what made for a good brief assignment, and furthermore a series of lightweight web apps to visualize and explore a set of assignments.
Rendering
The problem of rendering a shorthand falls into a very similar category. It’s theoretically possible to encode every rule of how the pen must move in order to realize a particular outline, but it would require extensive knowledge of vector graphics–and even then, who would bother?
In the case of Stolze-Smith, there is a single application that is both obvious and extremely narrow in scope. To properly document the system for human consumption, you have to provide written samples. Nothing else will do. In the case of Smith, the greatest manual effort was writing out the system illustrations and scanning them in.
In order to produce the manual for Stolze-Smith, I built an entire text-to-signs pipeline which, given English words, will render an SVG of the appropriate Smith-Stolze outline. For bonus points, I created a reStructuredText directive which will insert the rendered SVG into the HTML generated for the rest of the document.
The result is that the entire manual is programmatically generated; I can iterate on it by editing the RST, regenerating the HTML, and pushing it to Netlify.
I want neither to over- nor underapply the insights gleaned from this project to the work of computer programming in industry. I think there is much here that is meaningful when working with coding agents on any project; there is also much that’s only applicable to solo projects where the code is not the point. In the case of Stolze-Smith, there are about 40,000 lines of code—far too much for any sane person to write by themselves!–but they don’t need to keep operating after the system has been designed and generated.
Let that be the point! In the sphere of my interests, there are many, many questions and curiosities that could be satisfied with 40,000 lines of code and not with much fewer. There will be more strange things created that would never otherwise have breathed.
Built with Bagatto.